前言
上一篇文章,介绍了使用 redis json + redis search,使内容数据库 redis 支持存储和检索非结构化数据——JSON。
小红书上有读者留言,说“费内存”、“pinecone 不香吗”。再看IP所在地,美国的有之,新加坡的有之。我才明白了,pinecone 是很好用,可那是在国外。他们说的没有错。
向量数据库
今天这篇,说的是 qdrant,支持本地部署,Windows、Linux、macOS,跨平台支持。本地能用,服务端自然也可以,数据就可以完全在自己的“视野”范围内了。
1,仓库介绍
qdrant 的仓库地址:
使用rust开发,运行速度极快,生产环境稳定。特别是性能突出,官网给出了性能对比图:
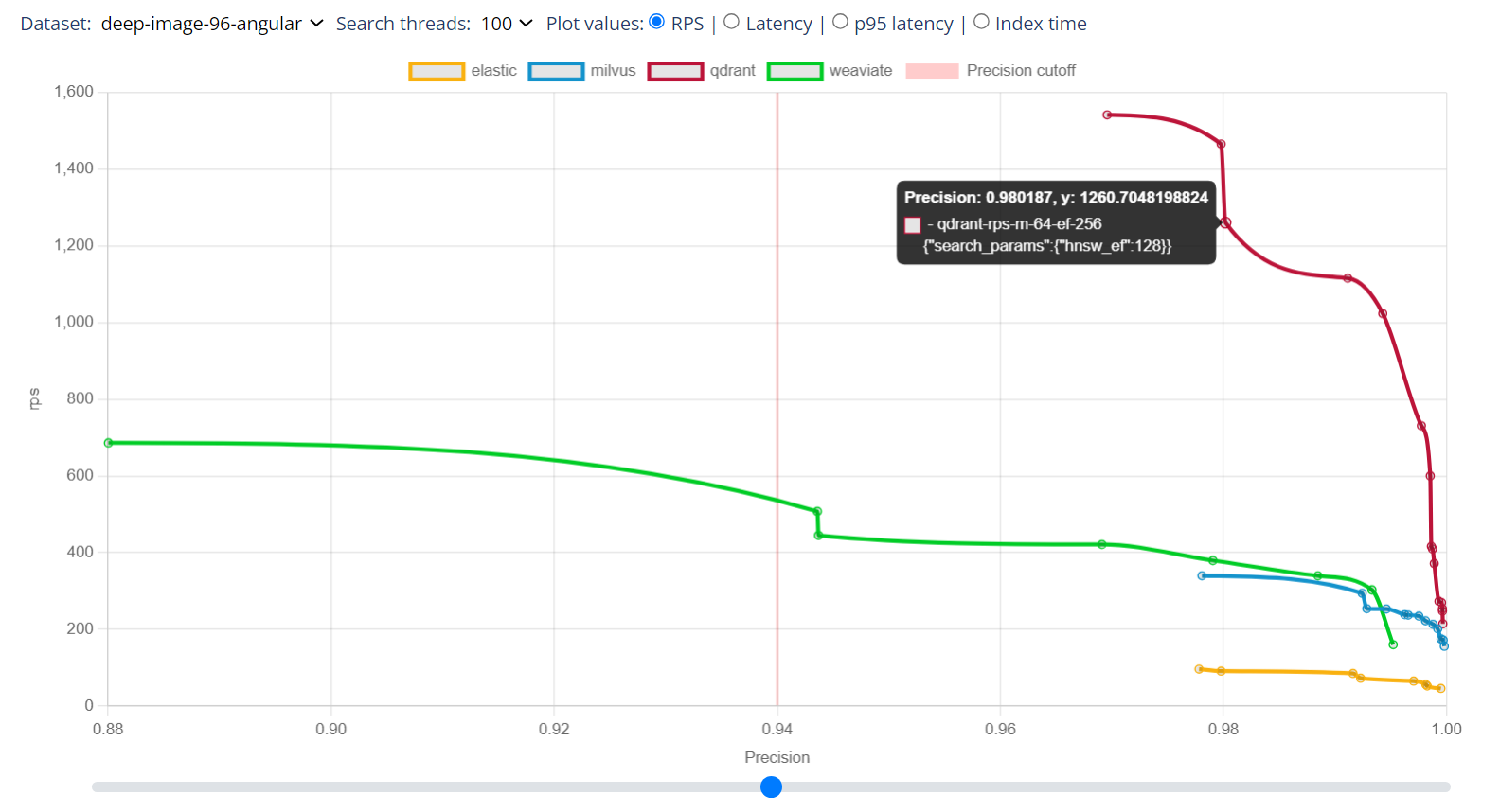
最上边的那条线,就是 qdrant。低压力测试下,没有曲线数据,好比是举重运动员要的起始重量。别的运动员,100kg开始,5公斤5公斤地加,等加到 130 公斤时,快累趴了。而 qdrant 上来就要的 150 公斤。如此理也。
2,本地部署
根据你本地的操作系统环境,去 release 页面选择对应平台,编译好的二进制文件。
| 文件名 | 大小 | 平台 |
|---|---|---|
| qdrant-aarch64-apple-darwin.tar.gz | 17.6 MB | iOS |
| qdrant-x86_64-apple-darwin.tar.gz | 15.8 MB | iOS |
| qdrant-x86_64-pc-windows-msvc.zip | 16.3 MB | Windows |
| qdrant-x86_64-unknown-linux-gnu.tar.gz | 16.9 MB | Linux |
下面以Windows平台下为例。下载文件后,解压,获取到 qdrant.exe 文件。运行命令查看是否正常:
|
|
在当前目录下,创建配置文件 config/config.yaml。
|
|
如果是服务环境,提供外部访问,host 参数设置为“0.0.0.0”。如果用到 grpc 功能,把 “grpc_port” 选项注释打开即可。
然后在命令行,直接运行服务:
|
|
运行成功如下图:
项目目录如下:
|
|
snapshots 存储快照;storage 存储数据。
3,测试服务
服务启动后,监听在配置文件中 http_port 指定的端口。默认 6333 端口。
我们使用 Windows 子系统 Ubuntu 22.04 LTS 版本下测试。使用 curl 执行以下操作:
|
|
调用 restful api 接口,快速创建一个集合 test_collection,并指定向量的配置。请求成功,返回类似以下json:
|
|
命令行写参数,发起请求,实在不便。qdrant 给各个语言的开发者,都提供了 sdk。
4,python sdk
python sdk 的封装,已发布为类库,提供安装使用。
|
|
实现一个最小可用的demo示例。
|
|
实例化 QdrantClient 客户端时,使用 memory 与sqlite的用法类似,数据存在内存中,代码释放,数据释放。
如果要连接到上一节的 qdrant 服务器,则使用
|
|
如果不使用本文所要讲的 openai 的embedding功能,qdrant 也提供了 embed 能力,可以在 CPU 或 GPU 上很好运行。使用的是 ONNX 运行时。只用再安装附加的 Python 类库。
|
|
这就可以了。提供的API很简洁,与正常的 QdrantClient 无异。
OpenAI
这一章介绍,把 openai 的向量数据,存储到 qdrant。以 Python 代码为例。
1,准备
首先连接到 qdrant 服务端。
|
|
2,加载数据
使用一份已向量化的数据集,作为测试数据。
|
|
你也可以手动,用下载器下载。zip 文件解压后,放在当前项目 data 目录下,仅包含一个 vector_database_wikipedia_articles_embedded.csv 文件,原始大小 1.7G。
3,数据读取
使用 pandas 读取数据,使用前,保证电脑内存充足。这 1.7G 的文件,是要整个放到内存里,供程序使用的。
|
|
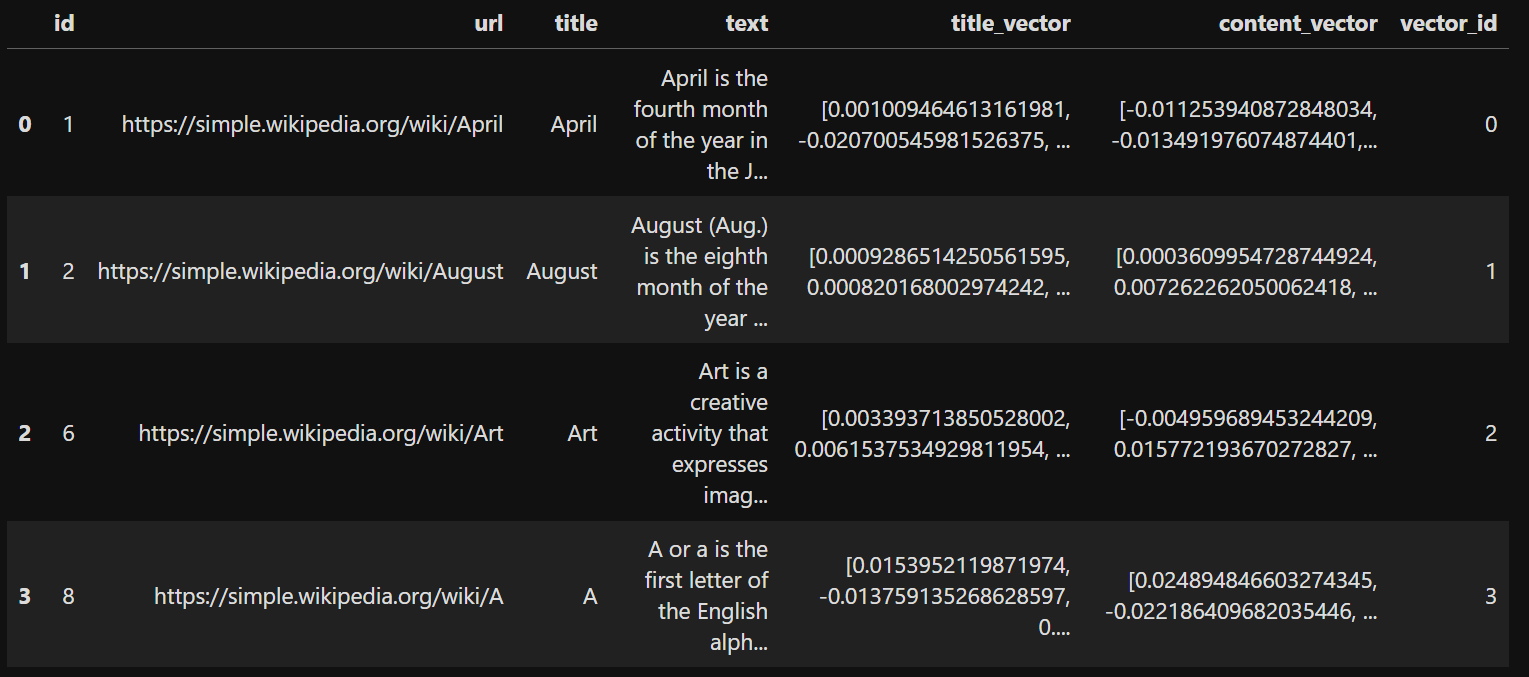
加载完成,打印前几行:
4,创建集合
在 qdrant 创建新的集合,并声明好集合的初始化参数。
|
|
集合 Articles 主要的两个字段 title, content,都事前指定数据量大小。然后遍历 pandas 列表,一行一行写写入到 qdrant 内。
|
|
upsert 方法,是update / insert的缩写。有则更新,无则创建。在非结构化数据库里,特别常用的一个方法。
5,助手函数
写一个助手函数,输入用户的查询语句,使用 openai 的 embedding 方法处理输入文本,并使用 qdrant client 搜索指定的集合。
|
|
6,搜索向量数据
使用上述 qdrant_search 方法测试:
|
|
搜索结果类似下方输出:
|
|
这样基本就完成了整个流程。
最后
本文详细介绍了 Qdrant 向量数据库,本地部署的详细方法。使用restful api方法,python客户端方式,连接到 qdrant 服务端。
qdrant 自带 embed 方法,可以节约 openai embedding 的费用。使用 ONNX 运行时,可在 CPU 主机上良好运行。
服务器有条件的,可以部署为独立的服务,支持自己的业务数据。
我是@程序员小助手,专注编程知识,圈子动态的IT领域原创作者。